Introduction
Apache Storm is an open-source real-time solution for data stream processing. The system steams unbounded data reliably, and it is an essential technological addition to Big Data systems. The computation program is flexible and finds many applications in data-based industries.
This article showcases the Apache Storm data streaming and processing system.

What Is Apache Storm?
Apache Storm is a distributed data streaming technology. Its main feature is processing large data volumes and high-velocity data streams. Apache storm is fast, processing over a million records per second per node on medium-sized clusters.
Note: Bare Metal Cloud servers are a great solution for automated bare metal cluster creation. Spin up servers quickly and automate cluster creation on BMC through a RESTful API within minutes. Check out the available BMC server instances and the BMC API guide to get started.
Businesses use Apache Storm in combination with other data processing applications in the Hadoop ecosystem for data optimization and the prevention of undesirable behavior.
Apache Storm vs. Spark
Apache Storm and Spark are two similar data streaming technologies. However, some differences in functionalities exist. Below is a brief table that helps demonstrate when to use which technology.
| Situation | Apache Storm | Apache Spark |
|---|---|---|
| Language Integration | Multi-language support | Python, R, Java, Scala |
| Stream Processing | Micro-batch and stream processing | Batch and micro-batch processing |
| Latency | Milliseconds | Seconds |
| Reliability | At Least Once At Most Once Exactly Once | Exactly Once |
Note: Check out our in-depth comparison of Apache Storm vs. Spark for more details.
Apache Storm Architecture
Apache Storm uses a master-slave architecture with the following components:
- Nimbus is the server residing on a single master node.
- Supervisors are services running on each worker node.
- Workers are single or multiple processes on each node started by supervisors. The workers run parallel data input handling and output the data to a database or file system.
- Zookeeper coordinates and manages the distributed data processes.
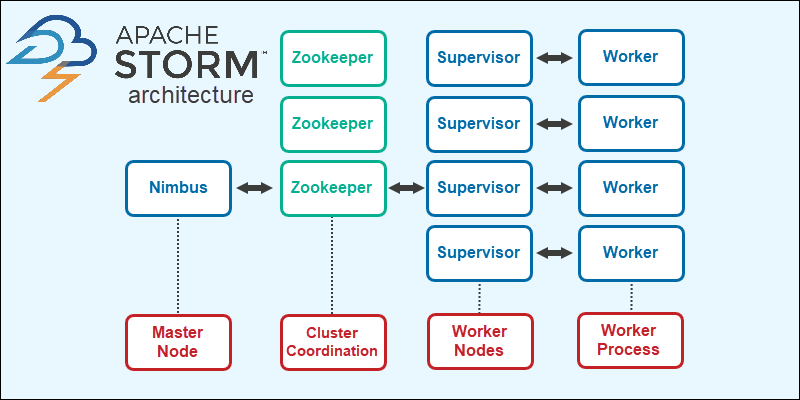
The architecture diagram shows an example Apache Storm configuration with 4 nodes. Each node has a supervisor process with multiple workers to retrieve and store data in a database or file system.
Apache Storm Topology
The Apache Storm topology is similar to MapReduce jobs in Hadoop. The topology consists of:
- Spouts are the data stream entry point in the topology. The spouts connect to the data source, retrieve data continuously, transform the information into tuple streams, and send the data to bolts.
- Bolts store the processing logic. The bolts run various functions, aggregations, stream joins, tuple filtering, etc. The output creates new streams for additional processing through other bolts or stores the data in a database.
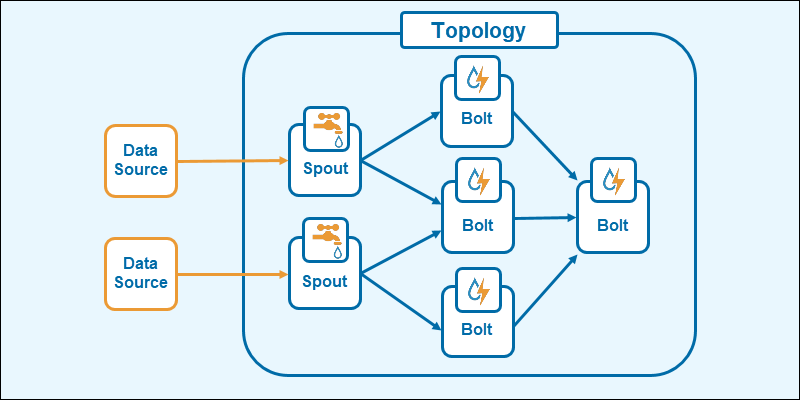
The topology features spouts on a single layer, whereas bolts may appear on multiple layers depending on the processing complexity.
Apache Storm Use Cases
Apache Storm thrives in massive data environments. Some notable use cases include:
- Spotify uses Storm for various real-time features, such as monitoring, analytics, recommendation systems, and targeting. With other technologies, such as Kafka and Cassandra, Storm enables a fault-tolerant, low-latency distributed system.
- Twitter uses Storm for both production and in-development applications. Some applications include real-time analytics, revenue optimization, discovery, and personalization.
- WebMD applies Storm in a mobile environment for NLP (natural language processing) tasks and real-time updates. Internal applications include ETL and marketing pipelines.
Apache Storm often serves as a backbone in enterprises for reliable data streaming, providing quick insights and results.
Advantages and Disadvantages of Apache Storm
Apache Storm deals with large amounts of data continually. Using the system yields certain advantages and disadvantages. Below are the benefits and drawbacks that come with using Apache Storm.
Advantages
The main advantages of using Apache Storm are:
- Affordability. Apache Storm is open source and free to use, making it an affordable solution for small and large businesses alike.
- Flexibility. Apache Storm provides flexibility by integrating into any programming language.
- Scalability. The system is highly scalable and adds additional resources linearly as data loads increase.
- Data processing guarantee. The distributed system ensures that data delivery happens in case of node downtime.
Disadvantages
The disadvantages of using Apache storm are:
- Tricky to install and configure for deployment. The system integrates with various other technologies. Creating these connections between Storm and other applications is sometimes tough.
- No framework-level support. Project development starts from scratch, making it difficult for new developers to pick up.
- Not suitable for smaller datasets. Apache Storm is a distributed system and not a good choice for small-scale applications.
Conclusion
After reading this guide, you know about Apache Storm and what the system brings to the data streaming world.
Next, learn how to implement the Streaming module in Apache Spark in our Spark Streaming guide for beginners.
