Introduction
ClickHouse is an open-source column-oriented database management system. It is a fast, scalable, and efficient software to use for data analysis updated in real-time.
It uses less memory and CPU than row-oriented databases since it does not have to process unnecessary data. Hence, it has a fast query response time, ultimately providing optimum performance. Additionally, it understands SQL, making it more user-friendly.
ClickHouse is highly flexible. You can run this management system on anything from bare metal servers to cloud servers, as well as on any Linux, MacOS or FreeBSD operating system.
This guide will show you how to install and get started with ClickHouse on your CentOS 7 server.

Prerequisites
- Access to a terminal window/command line
- A server running CentOS 7 with sudo privileges
- A text editor (such as Nano)
- SSH service to connect to your remote server
Connect via SSH and Update
1. Before you can install ClickHouse, you need to access your remote CentOS server.
Run the following command and replace your_username and host_ip_address with your respective specifications:
ssh your_username@host_ip_address2. Once you connect to the server, make sure to update the system by running the command:
sudo yum updateInstall ClickHouse on CentOS
1. First, install the software dependencies, which include the pygpgme package (for adding and verifying GPG signatures) and yum-utils (for source RPM management):
sudo yum install -y pygpgme yum-utilshere2. To install the latest version of ClickHouse, you have to access a YUM repository maintained by ClickHouse’s consulting firm, Altinity. However, you also want to ensure the installation package doesn’t harm your server.
Start by creating the repository file with a text editor of your choice (in this example, we used Nano):
sudo nano /etc/yum.repos.d/altinity_clickhouse.repo3. Then, add the following content to the newly created file:
[altinity_clickhouse]
name=altinity_clickhouse
baseurl=https://packagecloud.io/altinity/clickhouse/el/7/$basearch
repo_gpgcheck=1
gpgcheck=0
enabled=1
gpgkey=https://packagecloud.io/altinity/clickhouse/gpgkey
sslverify=1
sslcacert=/etc/pki/tls/certs/ca-bundle.crt
metadata_expire=300
[altinity_clickhouse-source]
name=altinity_clickhouse-source
baseurl=https://packagecloud.io/altinity/clickhouse/el/7/SRPMS
repo_gpgcheck=1
gpgcheck=0
enabled=1
gpgkey=https://packagecloud.io/altinity/clickhouse/gpgkey
sslverify=1
sslcacert=/etc/pki/tls/certs/ca-bundle.crt
metadata_expire=300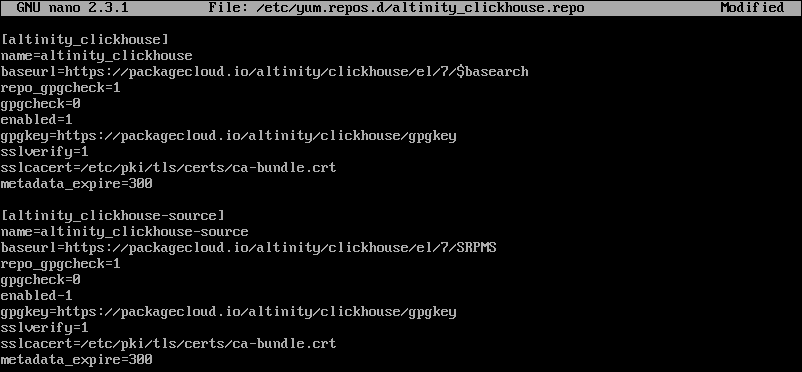
4. Save and close the repository file.
5. Next, enable the repositories with the command:
sudo yum -q makecache -y --disablerepo'*' --enablerepo='altinity_clickhouse'6. Once the output confirms you added the GPG key, you can move on to installing ClickHouse. Download the clickhouse-server and clickhouse-client packages with the following command:
sudo yum install -y clickhouse-server clickhouse-client7. With this you have installed ClickHouse on your CentOS 7 server.
How to Start ClickHouse Service
The systemd service created by the clickhouse-server package is responsible for starting, restarting, and stopping the database.
To start the ClickHouse server use the command:
sudo service clickhouse-server start hereThe terminal should display the following output:

You can also check whether the service is running correctly with:
sudo service clickhouse-server statusThe message you receive should be as in the image below:

How to Create Databases and Tables
To create databases and tables, you first need to start a client session. Once the prompt opens, you can use it to run SQL statements.
clickhouse-client --multilineWhile the clickhouse-client command opens a new session, the --multiline flag allows you to run queries that take up multiple lines.
Create a Database
A database is essentially a directory for tables. The syntax for creating a database is:
CREATE DATABASE db_nameNote: Alternatively, you can use the command: CREATE DATABASE [IF NOT EXIST] db_name. Adding the [IF NOT EXIST] clause prevents the query from creating a database or returning an error if it already exists.
The output will confirm the database has been created by displaying the message “Ok.”, along with the number of rows in set and the time it took to create.
To create a database on all servers from a cluster, add the [ON CLUSTER cluster_id] clause to the basic syntac:
CREATE DATABASE db_name [ON CLUSTER cluster_id]To retrieve data from a remote MySQL server to the newly created database add the [ENGINE = engine(…)] clause, as in the following command:
CREATE DATABASE db_name [ENGINE = engine(…)]Create a Table
The syntax for creating a table is:
CREATE TABLE table_name
(
column_name1 column_type [options],
column_name2 column_type [options],
) ENGINE = engineThe type of ENGINE you choose depends on the application. ClickHouse has its native database engine that supports configurable table engines and the SQL dialect.
Generally, MergeTree Family engines are the most widely used. However, ClickHouse also supports MySQL.
When creating a table, you first need to open the database you want to modify. Use the following command:
ch:) USE db_nameThe output will confirm you are in the specified database.
Next, you can create a table with all the wanted columns (and column types). In this example, we will create a Client table consisting of six (6) columns using the command:
ch:) CREATE TABLE Client (
ch:) ClientID UInt64,
ch:) FirstName String,
ch:) LastName String,
ch:) Address String,
ch:) City String,
ch:) BirthDate DateTime
ch:) ) ENGINE = MergeTree()
ch:) PRIMARY KEY ClientID
ch:) ORDER BY ClientID;A name and a column type define each column. The column types in the example include:
- UInt64: for storing whole numbers ranging from 0 to 18446744073709551615
- String: for storing text which can contain characters, numbers, and spaces
- DateTime: for storing dates and time in the format YYYY-MM-DD HH:MM:SS
In this case, the storage ENGINE is the most robust ClickHouse table engine – MergeTree.
Next, the PRIMERY KEY defines which column to use to identify all records of the table.
Finally, the ORDER BY clause lets you order the results based on the defined column.
Upon creation, the output should appear as following:
CREATE TABLE Client
(
ClientID UInt64,
FirstName String,
LastName String,
Address String,
City String,
BirthDate DateTime
)
ENGINE = MergeTree()
PRIMARY KEY ClientID
ORDER BY ClientID
Ok.
0 rows in set. Elapsed: 0.010 sec.Insert, Update, and Delete Data and Columns
To insert rows in a table, use the following query syntax:
INSERT INTO table_name VALUES (column_1_value, column_2_value, ....);For example, if we wanted to insert rows into the previously created Client table, we would run the following command:
TO BE ADDEDWhen adding new columns to a table, use the syntax:
ALTER TABLE table_name ADD COLUMN column_name column_type;For example, if you want to add a Profession column to the Client table, the command would be:
ALTER TABLE Client ADD COLUMN Profession String;To add multiple columns using the syntax:
ALTER TABLE table_name ADD COLUMN column_1 column_type, column_2 column_type, column_3 column_type;Note: Tables only support the ALTER query if they are MergeTree engines.
ClickHouse databases use non-standard SQL queries for updating and deleting, which include asynchronous batch operations. The following commands are available for versions 18.12.14 or newer.
The syntax for updating is:
ALTER TABLE table_name UPDATE column_1 = value_1, column_2 = value_2 ... WHERE filter_conditions;The syntax for deleting rows is:
ALTER TABLE table_name DELETE WHERE filter_conditions;The syntax for deleting columns is:
ALTER TABLE table_name DROP COLUMN column_name;Deleting Tables and Databases
To delete or drop a table, use the following syntax:
DROP TABLE table_nameIf we wanted to delete the Clint table, use the command:
DROP TABLE ClientThe syntax to completely delete a database is:
DROP database db_nameQuery or Retrieve Data
Use the SELECT clause to retrieve data from rows and columns. The basic syntax is:
SELECT func_1(column_1), func_2(column_2) FROM table_name WHERE filter_conditions row_options;If you want to retrieve single output values that summarize the values of multiple rows and columns, you can use aggregate functions.
Some examples of common aggregate functions supported by ClickHouse are:
• avg (average): calculates the average volume of selected column; only used for numbers
• count: calculates the number of rows that match the specified criteria
• sum (summation): calculates the sum of a numeric column; only used for numbers
• uniq: calculates the approximate number of rows matching the criteria; used for numbers, string, and dates
Conclusion
This guide should help you get started with the ClickHouse management system and how to install on a remote CentOS server. Additionally, it included the basic syntax for most common commands in ClickHouse.
If you are using Ubuntu, be sure to read our guide on ClickHouse installation on Ubuntu 20.04.
